
グローバル化によって、日本のビジネスにおいても世界標準語の英語や中国語のスキルが必要とされるようになっています。一方で、人工ニューラルネットワークによる自然言語の機械翻訳の精度も高まり、各種サービスも登場しています。このような状況でエンジニアは、英語(外国語)を学ぶ必要があるのでしょうか? この疑問を探るべく、国立研究開発法人情報通信研究機構(NICT)のフェローで自動翻訳の専門家・隅田 英一郎 博士に、最新の技術動向についてお聞きしました。

用例翻訳と深層学習によって、精度が高まってきた機械翻訳
――最近のビジネスパーソンは英語を学習すべきと言われていて、私自身も英語を学習しています。しかしその一方で自動翻訳などのテクノロジーも進化しており、ビジネスの場でも活用されています。エンジニアなら英語を学習しなくても、テクノロジーを使って乗り切れるものでしょうか? 隅田さんはエンジニアと英語学習の関係についてどんなイメージをお持ちですか?
理系出身の方たちは数学と理科が得意な反面、英語が苦手な人も多いかもしれません。でも、最新の技術資料ドキュメントはほとんど英語なので、英語は避けて通れません。英語ができないことで最新の技術をいち早く得られないといった状況になりかねないのです。そこで自動翻訳です。まずは、私たちNICTが提供している「みんなの自動翻訳@TexTra(テキストラ)」でどんなことができるかを紹介します。

日本を入力して英語に翻訳してみる
画像提供:情報通信研究機構(NICT)
文章を入力して翻訳した英語をクリックすると、原文と翻訳文の他に逆翻訳というものが出てきます。これは一度翻訳した英文を再度日本語に翻訳しなおしたものです。原文と逆翻訳を見比べることで、英文の内容がはっきりわからなくても、翻訳された内容が正しいかどうかを判断できるのです。日本は英語学習者が多いため英語はなんとかなりそうですが、中国語やヒンディー語などの言語になってくると翻訳の正確性はわからない人がほとんどだと思います。そんなときに逆翻訳があると便利ですね。
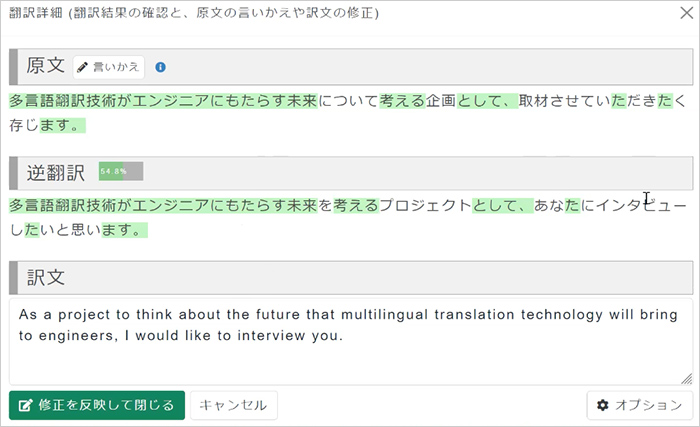
訳文をさらに日本語訳した逆翻訳が表示される
画像提供:情報通信研究機構(NICT)
また、このツールには金融や特許など、専門分野に分かれた翻訳システムがあって、翻訳したい分野に合わせてシステムを選ぶことができます。例えば金融では、東京証券取引所の適時開示などを翻訳できるように、東京証券取引所のデータを大量に学習しています。また、法務省が翻訳した日本の法律のデータを入れてある法令翻訳や医療翻訳、製薬翻訳などのさまざまな専門的な翻訳システムがあります。

汎用システムの翻訳結果と金融特化システムの結果を比較
画像提供:情報通信研究機構(NICT)
汎用システムの性能は Google翻訳やDeepL翻訳、そしてNICTのものは、そんなに変わりませんが、NICTの専用翻訳システムは専門分野において、より精度が高く修正が少なく済むという点で優れています。
――音声の翻訳はどうなっていますか?
このサイトでは対応していませんが、私達の研究成果はAI翻訳機の「ポケトーク」、スマホ用の多言語音声翻訳アプリ「VoiceTra(ボイストラ)」でも使われていて、観光などの目的であれば十分実用性があります。

VoiceTra(ボイストラ)のサイト https://voicetra.nict.go.jp/
画像提供:情報通信研究機構(NICT)
VoiceTraにも逆翻訳がついています。この逆翻訳機能は10年前からあって非常に好評なんです。アプリはシリーズ累計で800万近くダウンロードされています。観光だけでなく、外国から働きに来ている人々とのコミュニケーションや、日本人が自身で英語の発音を試すなど語学アプリとしても使われているようです。VoiceTraやTexTraは無料で使えますので、気軽に体験してみてください。
――技術について教えてください。現在の自動翻訳システムはどんな仕組みになっていますか?
現在の翻訳システム(ニューラル翻訳)は、深層学習によって翻訳の知識を人工ニューラルネットとして作っています。システムを学習させるためには、原文と翻訳結果のデータが必要で、各所からデータを集めています。学習データとして与えた情報が外部に漏れるのではないかと心配する人もいますが、結果として出力されるのは数字の塊で、もとのデータの文章はどこにも漏れないようになっています。

原文と翻訳文のセットを入力し、学習させるが、結果は数値の羅列のため秘密は守られる
画像提供:情報通信研究機構(NICT)
VoiceTraでは31言語を翻訳できるようになっています。アジアに強いので、コロナ禍がなければ海外観光客は1000万人、2000万人、3000万人と急増していましたので、インバウンド需要でもっと使われていたと思います。
自動翻訳のシステムは1945年から研究の歴史がありますが、今の技術は2010年代からはじまるニューラル翻訳の以前、1980年代からの技術がベースになっています。1984年に京都大学の長尾 真 先生が「EBMT(Example Based Mechanical Translation:用例翻訳)」というものを考えました。例文を集めて、それをもとに翻訳をすればいいというアイデアなのですが、当時は斬新すぎて学会で注目されませんでした。これは非常に先見性があって、現在のニューラル翻訳というのはデータを与えてシステムを作るというものですので、長尾先生のアイデアに技術が追いついてきたのです。
TexTraでは、普通のニューラル翻訳に加えて、長尾先生のEBMTも実装されていて、これによって全体のパフォーマンスを著しく高めているのです。例文として保存された対訳とマッチすれば、非常に高い精度の翻訳が可能で、時には平均的な翻訳者よりも良い結果を出すことができます。
――NICTが行っている、企業や自治体から原文と外国語の対訳文を集める取り組み「翻訳バンク」のデータが使われているということですか?
そうですね。翻訳バンクで集めたものは全部が完璧なデータではないです。ニューラル翻訳では量が重要なのですが、EBMTでは例文の質が重要になってきます。翻訳システムを作るときは、集約した全データを入れて、汎用のシステムを作ります。次に、専門分野のために特定データを10万文から100万文集めて、その分野に強いシステムを作ります。
例えば「study」という英単語は「勉強」「学問」「研究」など様々な意味を持っていますが、製薬関係の例文を100万文集めてくると、「study」は「治験」と訳されることが多いです。このように、たくさんの訳の中から、専門分野に適した訳を選ばせるのがこの第2のステップの「分野適応」です。

同じ単語でも分野が変われば訳も変わるため、分野適応は重要
画像提供:情報通信研究機構(NICT)
そしてさらにその次に「個社適応」があって、これがExample Basedです。これはつまり、見本そのものを用いるということです。そうすると特定の会社で使うような表現にできます。さらに、特定の個人が使うような表現に合わせることもできるようになります。例えば翻訳者のAさんがいたとして、その人が過去に翻訳したデータを学習すると、Aさんの分身となるシステムができます。そのシステムの翻訳結果は、Aさんのスタイルを踏襲しているため、Aさんはゼロから翻訳せずに少し修正すれば済みますので、仕事がすごく楽になります。技術はそこまで進んでいるのです。
自動翻訳システムが、日本の社会課題を解決する
――インターネットなど、IT技術の普及によって世界が近くなりました。そのなかでもビジネスやテクノロジーでは英語がスタンダードになっていますね。
英語は世界的に特別な存在になっていて、みなさん英語を勉強しなければいけないことになっています。逆に、もともと英語ができる人は英語以外の言語を勉強しなくていいという、非常に不公平な状態です。この状況は簡単には変わりません。
日本人が、英語を苦手としているのは、普段の生活にあまり必要がないからです。英語を学習することで経済的にメリットがある国に住む人は学習しますが、日本人は日本の中だけで暮らせるので、今のままでよかったら英語の学習は必要ないです。
しかし、OSS(オープンソースソフトウェア)の世界などでは話が違います。今は新しいOSSの技術がどんどん登場していますね。それらのドキュメントは日本語ではありません。日本のエンジニアにとっては大きな障害になっているのです。そこでNICTでは、The Linux FoundationというOSSのコミュニティと提携して、これらのソフトウェアのドキュメントに自動翻訳を入れて日本語化しています。コミュニティには翻訳者がいて、対訳データを作り、それをNICTにアップロードして精度を高めるという循環ができています。

NICTプレスリリース―オープンソースのコミュニティにNICT「みんなの自動翻訳」を提供―より
画像提供:情報通信研究機構(NICT)
また、「みんなの自動翻訳」は、オープンソースのコミュニティの人が自由に使えるようにしてあります。オープンソースのオフィスソフト「LibreOffice」のマニュアルを全て自動翻訳して公開できるくらいに性能は高いです。もちろんある程度の誤訳もありますが、読む方がその前提を理解して読めば問題なく利用できるでしょう。
――自動で日本語化されるのは便利ですね。世界のなかで、日本語の置かれている状況についてどのようにお考えですか?
一般論ですが、外国のニュースなどが日本語化されている、また日本の情報がどれだけ外国語に訳されているのか調べてみると、どちらも全情報の10分の1ぐらいにしかなりません。例えば、海外の記事は、日本人にとって必要だと考えられるものだけが翻訳されて、残りの90%の記事は捨てられてしまいます。その選択の際にバイアスがかかってしまって、重要な情報を多くの国民が知らないという状況になっています。
具体例では、たとえば新型コロナのワクチンの情報ですね。ワクチン1瓶あたり標準的な注射器だと接種回数が6回ではなくて5回しか取れないという情報が日本に入ってきたのは、発信されてから1ヶ月も経ったあとでした。どこかで誰かが選んだ情報だけを使っているせいで、こういった情報不足が起こってしまいます。
また逆も同様で、東京証券取引所に上場している国内企業の情報も10社中1社程度しか英訳されていません。だから、日本の市場は透明性がないと言われてしまいます。そういう意味でも、自動翻訳でもいいから日本の情報を積極的に外へと出していくべきだと思います。
さらに、これからの日本の社会について考えてみましょう。少子化が進み、外国人が労働力として入ってきて、外国語が必要になります。しかし勉強するのは大変です。そこで自動翻訳が日本を救うわけです。

日本社会が抱えるさまざまな課題は、自動翻訳によって解消される
画像提供:情報通信研究機構(NICT)
エンジニアの人が英語を学習しようと思ったら、多くの時間を費やしてしまいます。英語ではなく、中国語がビジネスの主流になるような動きがあれば中国語を、その他アジアの国々が伸びてきたらアジアの言語を学習しなければいけなくなります。それはとてもコストパフォーマンスが悪いですね。だから自動翻訳を活用するべきなのです。
みんなが自動翻訳を使うようになると、英語は特別な存在ではなくなります。言葉が対等になるんですよ。そういう可能性を自動翻訳は持っているのです。

言葉の壁がなくなることで、ローカルとグローバルのバランスがとれる
画像提供:情報通信研究機構(NICT)
大阪万博が開催される2025年には自動同時通訳機が普及
――言葉が対等になるという考えはすばらしいですね。自動翻訳のレベルは今どれくらいで、どのような効果が得られるようになっているのですか?
音声翻訳の性能は2021年の時点においてTOEICスコア900くらいのところにいます。音声認識の単語の正解率ではAIは人間を上回っています。例えば、英語を聞くためのAIを使うと、音声を文字化するところだけはネイティブと全く同じレベルまでいけます。

音声認識はAIのほうが速さと正確性ともに人より優れている
画像提供:情報通信研究機構(NICT)
実際、自動翻訳というのは役に立っています。ある製薬会社では自動翻訳を使うことで、治験実施計画書の制作期間が半減しました。従来のやり方では、翻訳を終えてから校正やチェック、修正をする工程に4週間かかっていました。しかし、自動翻訳を使うことで、翻訳の時間がほぼ0になって、校正と修正の時間を合わせても2週間になったんですよ。コストは半分に減りますし、患者さんのもとに薬がより早く届くようになります。

自動翻訳によって1日も早く薬が認可されるようになるのは万人にとって大きなメリット
画像提供:情報通信研究機構(NICT)
NICTは特許庁も連携しています。特許は外国語にして出願しなければならないし、外国特許を読まなければいけません。今の特許は半分以上が中国語です。だから、例えば中国に製品を輸出するときに自社の製品が特許に触れていないかどうか、中国特許を調べなければなりません。言語の壁を解消するために特許の対訳データから自動翻訳システムを構築しています。
このシステムは、東芝の言語処理技術とNICTの翻訳エンジンを組み合わせており、5000文字程度であれば6秒で応答します。特許庁でこれを一般に公開し、日常的に使われていて、非常に好評です。翻訳精度は、現在広く使用されている機械翻訳の評価方法であるBLEUスコアだけでなく、RIBESという機械翻訳の結果を自動的に評価する尺度においても、Google翻訳よりNICTの方が優れていることが証明されています。
この背景には、先ほど話題に出た「翻訳バンク」があり、2017年から企業や自治体が持っている翻訳データを集めて翻訳システムに役立てています。みなさんに提供いただいたデータが溜まって性能がどんどん良くなっているのです。

日本全体で自動翻訳をつくるプロジェクト「翻訳バンク」(https://h-bank.nict.go.jp/)
画像提供:情報通信研究機構(NICT)
――ますます便利になりますね。自動翻訳は、将来的にはどこまで発展しそうですか?
現在、逐次通訳から同時通訳を目指しています。ポケトークなどの翻訳ツールは逐次翻訳です。言葉を聞いて、翻訳した言葉を再生するので、同じ意味の言葉が言語を変えて2回発せられます。30分の会話をしようと思ったら1時間かかりますね。そうなると、ビジネスコミュニケーションとしては非常に無駄となります。これを同時翻訳にできたら、相手が30分喋ったら、その30分の間に内容を理解できることになります。
オフショア開発で海外のエンジニアとやりとりすることもあるでしょう。Zoomの会議やSlackでのやり取りに自動翻訳が入ったらいいですよね。わざわざ英語を介さずに、お互いの第一言語で会話ができるようになるという考え方です。
同時翻訳システムを2025年までに実現させようという国の計画に「グローバルコミュニケーション計画2025」があります。総務省の予算で動いていて、同時翻訳を世界に先駆けて出していくというのが我々のミッションで、2025年の大阪万博までに同時翻訳システムを市販レベルにまでにする計画です。技術的には今の時点でかなりいいところまで来ています。その後は、より高度な会話や交渉に使えるようにステップアップしていきたいと考えています。

2030年にはシビアな交渉にも使える同時通訳の実現を目指す
出典:総務省 グローバルコミュニケーション計画2025
英語は高校レベルでOK。自動翻訳で世界中の人と話し、多様な視点を持つことが重要
――これだけ自動翻訳が進化している社会で、エンジニアやビジネスパーソンが仕事のために、多くの時間を割いて英語を学習する必要はあるのでしょうか。
90%の日本人は英語を必要としていないと思います。そういう人たちは必要なときに既にできている自動翻訳機能を使えばいいので学習の必要はありません。仕事で英語を使う日本人は全体の10%ぐらいではないでしょうか。こういう人々が自動翻訳をビジネスで使いこなすには、高校卒業レベル程度の英語力が必要なので、そこまでの勉強はするべきです。ですから、高校レベルの英語を身につけているエンジニアさんたちは、自動翻訳システムを使えばいいでしょう。ごく一部の英語に精通する必要がある職業の場合のみ、好きなだけ勉強すればいいと思います。
アメリカ人が外国語を勉強するとなったとき、日本語や韓国語が一番難しくて、フランス語の600時間に対して2200時間もかかるという統計があります。逆も同じで、日本人が英語を勉強するときには最低でも2200時間かかるということになっています。日本人は中学と高校でだいたい1000時間英語を学習しています。だから、あとは自動翻訳を使えばいいという話ですね。
高校レベルの英語力が必要だと言った理由は、自動翻訳の誤訳を見極めるためです。自動翻訳は9割の精度と言われていますので、1/10の誤りを見つけて正すことができる英語力は必要なわけです。
――多くのAIが使われる時代に、エンジニアはどんなことに注力していけばいいのでしょうか?
自動翻訳はAIの典型例ですので、ぜひ使ってみてください。「みんなの自動翻訳」は無料で使えてAPIも公開していますので、価格交渉もなければ上司への承認も必要ないです。それから、ほかのAIもどんどん活用してください。
いつも同じ情報源ばかり見るのもよくないので、さまざまな観点で考察するためのスキルを身につけることが重要です。それから、いろいろな人と喋ってコミュニケーションスキルを磨いてください。そのときにも自動翻訳が役に立つでしょう。
私が最後にみなさんにお伝えしたいのは「No MT No Life」〜自動翻訳(Mechanical Translation)なしには生きていけない〜です。みんなで自動翻訳を使っていきましょう!

――自動翻訳がエンジニアに力を与え、日本を救う未来が見えました。英語の勉強はほどほどでいいようです。隅田博士、ありがとうございました!








